
I would like to draw draw attention to the following Openwall’s tweet:
and the full post on LKRG’s mailing list here:
https://www.openwall.com/lists/lkrg-users/2020/06/14/5
Thanks,
Adam
15
May
CVE-2020-12826 is assigned to track the problem with Linux kernel which I’ve described in my previous post:
CVE MITRE described the problem pretty accurately:
A signal access-control issue was discovered in the Linux kernel before 5.6.5, aka CID-7395ea4e65c2. Because exec_id in include/linux/sched.h is only 32 bits, an integer overflow can interfere with a do_notify_parent protection mechanism. A child process can send an arbitrary signal to a parent process in a different security domain. Exploitation limitations include the amount of elapsed time before an integer overflow occurs, and the lack of scenarios where signals to a parent process present a substantial operational threat. |
RedHat tracks this issue here:
https://bugzilla.redhat.com/show_bug.cgi?id=1822077
Debian here:
https://security-tracker.debian.org/tracker/CVE-2020-12826
Fix can be found here:
https://github.com/torvalds/linux/commit/7395ea4e65c2a00d23185a3f63ad315756ba9cef
What is interesting, the story of insufficient restriction of the exit signals might not be ended 😉
In short, the following patch reintroduces the same problem:
Best regards,
Adam
I’ve recently spent some time looking at ‘exec_id’ counter. Historically, Linux kernel had 2 independent security problems related to that code: CVE-2009-1337 and CVE-2012-0056.
Until 2012, ‘self_exec_id’ field (among others) was used to enforce permissions checking restrictions for /proc/pid/{mem/maps/…} interface. However, it was done poorly and a serious security problem was reported, known as “Mempodipper” (CVE-2012-0056). Since that patch, ‘self_exec_id’ is not tracked anymore, but kernel is looking at process’ VM during the time of the open().
In 2009 Oleg Nesterov discovered that Linux kernel has an incorrect logic to reset ->exit_signal. As a result, the malicious user can bypass it if it execs the setuid application before exiting (->exit_signal won’t be reset to SIGCHLD). CVE-2009-1337 was assigned to track this issue.
The logic responsible for handling ->exit_signal has been changed a few times and the current logic is locked down since Linux kernel 3.3.5. However, it is not fully robust and it’s still possible for the malicious user to bypass it. Basically, it’s possible to send arbitrary signals to a privileged (suidroot) parent process.
I’ve summarized my analysis and posted on LKML:
https://lists.openwall.net/linux-kernel/2020/03/24/1803
and kernel-hardening mailing list:
https://www.openwall.com/lists/kernel-hardening/2020/03/25/1
Btw. Kernels 2.0.39 and 2.0.40 look secure 😉
Thanks,
Adam
21
Mar
On 28th of February, I’ve sent a short summary to lkrg-users mailing list (https://www.openwall.com/lists/lkrg-users/2020/02/28/1) regarding recent Linux kernel XFRM UAF exploit dropped by Vitaly Nikolenko. I believe it is worth reading and I’ve decided to reference it on my blog as well:
Read moreSome time ago I’ve found an interesting memory corruption bug (via integer overflow) in the mechanism responsible for parsing XMSS private keys. This bug is addressed in the latest OpenSSH released version (8.1) and more details about the bug can be found here:
CVE-2019-16905 – OpenSSH Pre-Auth XMSS Integer Overflow
Best regards,
Adam
Felix Wilhelm recently tweeted a Proof of Concept (PoC) of container escape abusing release agent for cgroup v1.
To be able to perform the attack, container was run with the “–privileged” flag which is not a setup for security anyway. When using this flag, containers have full access to all devices and lack restrictions from seccomp, AppArmor, and Linux capabilities. Nevertheless, “–privileged” flag is just a simplification of the necessary requirements for this attack, which is SYS_ADMIN capability for the container itself, as well as VFS for cgroup v1 mount with the read and write permission.
Felix was able to inject a custom command into the mechanism known as a “notify_on_release” in cgroup v1. When the last task in a cgroup leaves it, a release agent is executed by the kernel via call_usermodehelper_exec() (UserModeHelper – UMH) mechanism. Since the kernel is doing ‘clean-up’, UMH is executed on the host outside of the namespace / container.
More information about release_agent can be found here:
https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt
Linux Kernel Runtime Guard (LKRG) has functionality of limiting an UMH interface. By default, it is allowed to execute only LKRG’s whitelisted programs. For some people it might be not enough and in that case LKRG has an ability to fully lock UMH and nothing can be executed via this interface. This might break things if your distro uses UMH to invoke any programs e.g. if you are using release_agent 😉
You can see how LKRG can save you by preventing and detecting Felix’s container escape (based on UMH) here:
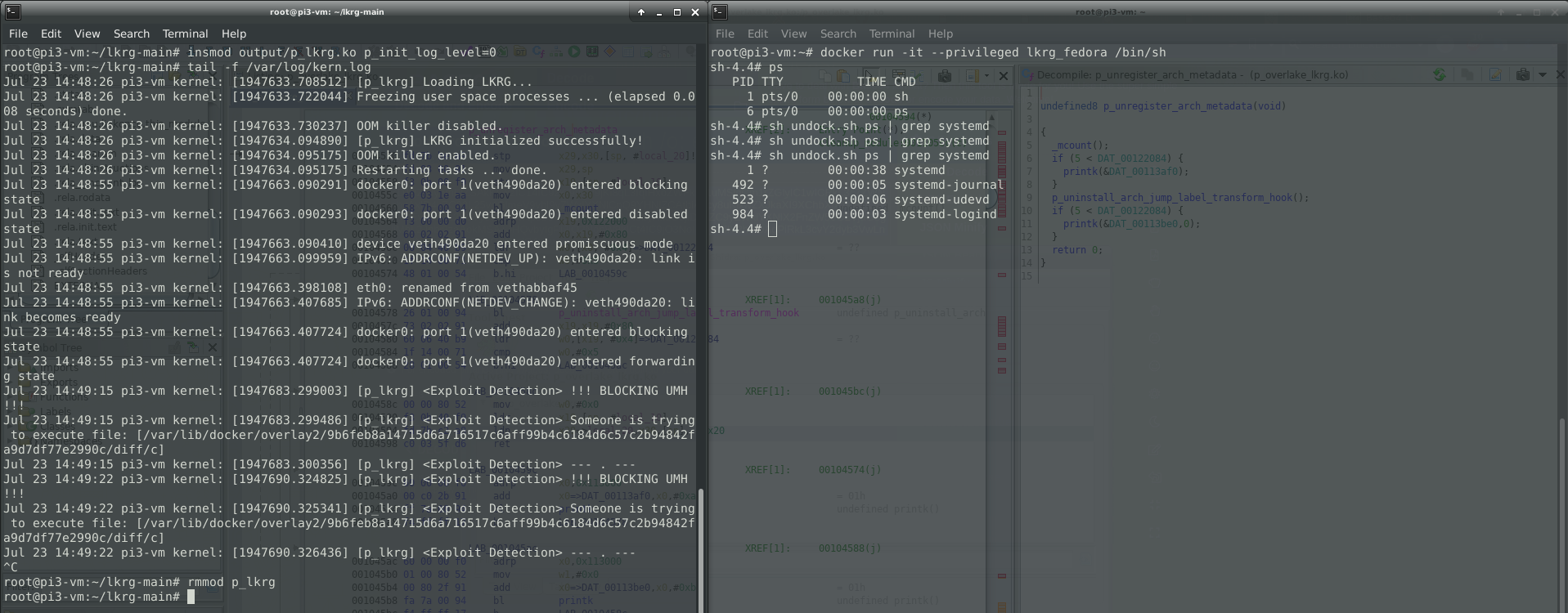
Thanks,
Adam
22
Jul
Hi,
We’ve just announced a new version of LKRG 0.7! As I’ve promised, now we have ARM support (AArch64). Additionally, LKRG can now be run under GRSecurity kernels. This release includes a lot of changes and I encourage to read full announcement here:
https://www.openwall.com/lists/announce/2019/07/21/1
Best regards,
Adam
14
May
Some time ago I took a look at i915 driver a bit. During my research I had found a few problems which had been fixed. Today (14th of May 2019), Intel announced the fix for reported security bug in i915 driver when Graphical Virtualization (GVT) is enabled under KVM (CVE-2019-11085 / INTEL-SA-00249). To be more specific, Intel’s vGPU driver allows for mappinng of arbitrary physical page into the context of calling process via mmap()
Additionally, Linux kernel community fixed two other bugs:
“[1/2] drm/i915: Prevent a race during I915_GEM_MMAP ioctl with WC set”
https://patchwork.kernel.org/patch/10750161/
“[2/2] drm/i915: Handle vm_mmap error during I915_GEM_MMAP ioctl with WC set”
https://patchwork.kernel.org/patch/10750163/
These bugs are pretty interesting from the pure research perspective so it is worth to take a look at the published patches.
Thanks,
Adam
3
Apr
One of the author of Windows Internals (Andrea Allievi) asked me and my friend David Kaplan if we could write a section about System Guard Runtime Attestation for their book. We’ve written about 3-4 pages describing internals of that project which we fully designed. Our section will be included in Windows Internals 7th edition part 2 (release date around August 2019):
Windows Defender System Guard Runtime Attestation (SGRA / SGRM) is internally known as a project Octagon which me and Dave fully designed and implemented together with Octagon v-team. Octagon is now included in every Windows build and first implementation of this new technology has been introduced in Windows 10 April 2018 Update (RS4). You can learn more about this project here:
Best regards,
Adam
19
Feb
Hi,
We’ve just announced a new version of LKRG 0.6! This release is… BIG! A few words why:
- We've introduced a new mitigation features which we call "poor's man CFI" (pCFI). It is designed to "catch" exploits which corrupts stack pointer to execute ROP and/or execute code not from the official .text section of the kernel (e.g. from the heap page, or user-mode page)
- We are using pCFI to enforce SMEP bit in CR4 and WP bit in CR0. If attacker disables one of that bits, LKRG will re-enable it again
- We've locked-down usermodehelper (UMH) interface - it will kill "class" of exploit abusing UMH
- We've completely rewrote *_JUMP_LABEL support - now it is independent of CPU architecture and can work on any CPU. Previously it was designed for x86 arch. New *_JUMP_LABEL support logic significantly reduce memory footprint, remove whitelisting, simplifies some algorithms and so on...
- We've introduce early boot systemd script/unit. Now you can easily manage LKRG service as any other service in the system. Systemd is the only init system which we support for now, but there is no reason to add support for other systems.
- We've fixed a few known problems with LKRG and made it more stable
- We've made all necessary changes to run LKRG on latest kernels
- A few more!
It’s a big release with a lot of changes. Full announcement can be found here:
https://www.openwall.com/lists/announce/2019/02/19/1
Next, I would like to work on ARM support for LKRG. Stay tuned….